A year ago I would just read about 397B league of models. Today I can run it on my laptop. The combination of llama.cpp’s importance matrix (imatrix) with Unsloth’s per-model adaptive layer quantization is what makes it all possible
Qwen3.5-397B-A17B is an 807GB beast that, even at Q4, would need more than 200GB of GPU RAM. Some people even call it “local”.
I have fairly strong laptop: M5 Max MacBook Pro 128GB (40-core GPU). That’s 128GB unified RAM, most of which I can dedicate to GPU. So 200GB+ is not something I can comfortably run on it. I could via ssd + ram, but it would be more of an experiment rather than putting the model to work.
But Qwen 397B is an MoE model: it has 512 experts and only routes to 10 of them per token, so the other 502 can be quantized way below Q4 without hurting that particular inference. imatrix keeps the important weights close to their original values, Unsloth’s adaptive layer quantization figures out which layers can afford to be stronger quantized. The combination of all makes 397B at just ~2 bits to fit in 106GB, which, according to my test, retains a surprising amount of its intelligence. And on top of all that.. 106GB is my laptop territory.
The model is “Qwen3.5-397B-A17B-UD-IQ2_XXS“:
- “UD” = Unsloth Dynamic 2.0, different layers are quantized differently
- “I” / imatrix = most important weights are rounded to minimize their loss / error
- “XXS”: extra, extra small.. 807GB => 106GB
After downloading it, before doing anything else I wanted to understand what it is I am going to ask my laptop to swallow:
$ ll -h ~/.llama.cpp/models/Qwen3.5-397B-A17B-UD-IQ2_XXS/UD-IQ2_XXS total 224361224 -rw-r--r-- 1 user staff 10M Apr 12 18:50 Qwen3.5-397B-A17B-UD-IQ2_XXS-00001-of-00004.gguf -rw-r--r-- 1 user staff 46G Apr 12 20:12 Qwen3.5-397B-A17B-UD-IQ2_XXS-00003-of-00004.gguf -rw-r--r-- 1 user staff 14G Apr 12 20:57 Qwen3.5-397B-A17B-UD-IQ2_XXS-00004-of-00004.gguf -rw-r--r-- 1 user staff 46G Apr 12 21:12 Qwen3.5-397B-A17B-UD-IQ2_XXS-00002-of-00004.gguf |
Here is the 106GB. The original 16bit model is 807GB, if it was “just” quantized to 2bit model it would take (397B * 2 bits) / 8 = ~99 GB, but I am looking at 106GB, hence I wanted to look under the hood to see the actual quantization recipe for this model:
$ gguf-dump \ ~/.llama.cpp/models/Qwen3.5-397B-A17B-UD-IQ2_XXS/UD-IQ2_XXS/Qwen3.5-397B-A17B-UD-IQ2_XXS-00002-of-00004.gguf \ 2>&1 | head -200 |
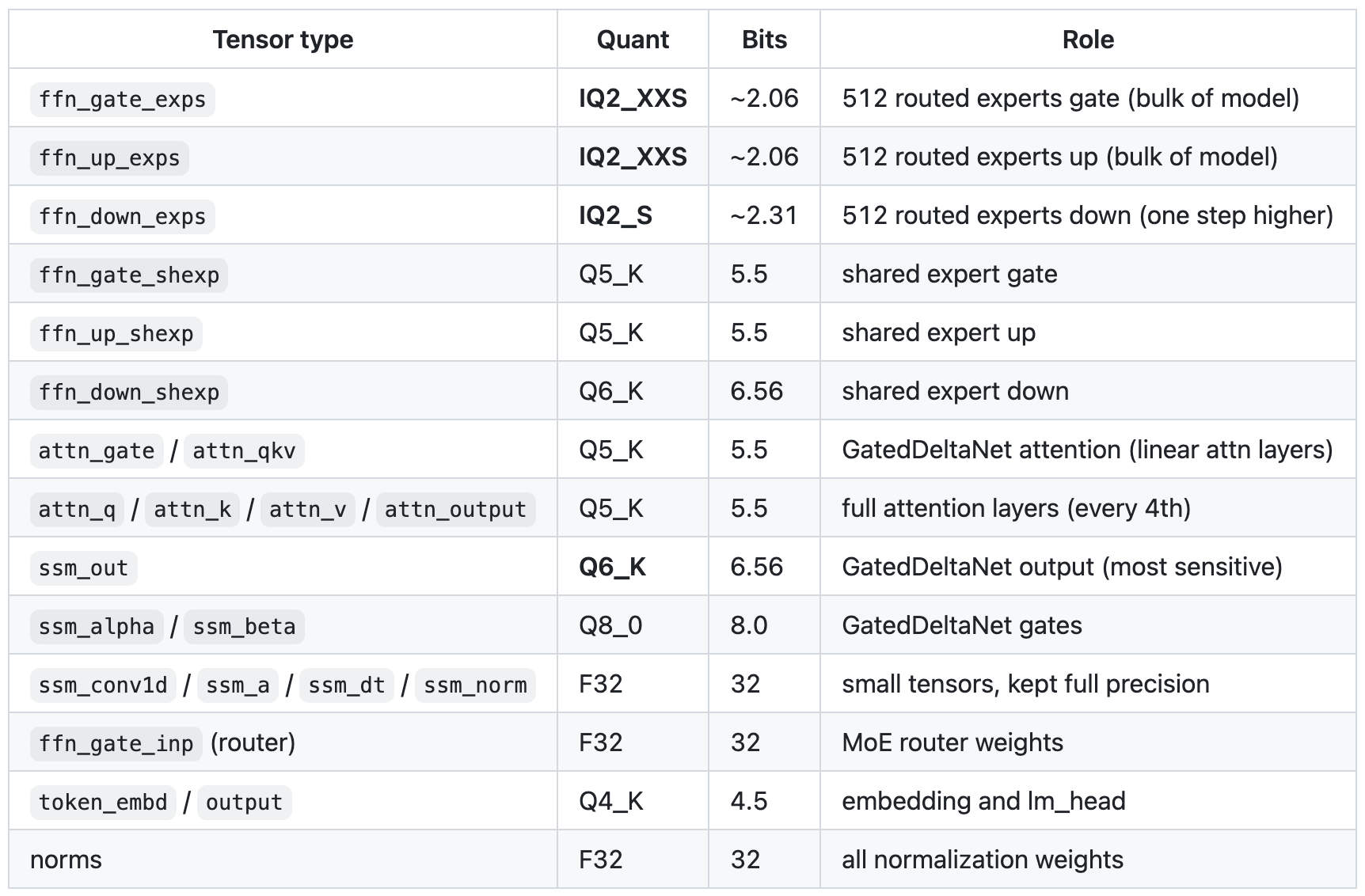
super interesting. the expert tensors (ffn_gate_exps, ffn_up_exps and ffn_down_exps) are quantized at ~2 bits, but the rest are much larger. This is where the 7GB difference (99GB vs. 106GB) really pays off: 7GB of packed intelligence on top of expert tensors.
trial by fire
By trial and error I found that 16K for the context would be a sweet spot for the 128GB unified memory. but the GPU space needs to be moved up a little to fit it (it is around 96GB by default):
$ sudo sysctl iogpu.wired_limit_mb=122880 |
“llama.cpp” would be the best choice to run this model (since MLX does not quantize to IQ2_XXS):
$ llama-server \ -m ~/.llama.cpp/models/Qwen3.5-397B-A17B-UD-IQ2_XXS/UD-IQ2_XXS/Qwen3.5-397B-A17B-UD-IQ2_XXS-00001-of-00004.gguf \ --n-gpu-layers 99 \ --ctx-size 16384 \ --temp 1.0 --top-p 0.95 --top-k 20 |
My current use case, as I described here, is finding the best model assembly to help me making sense of my kids school work and progress since if anything is super messy in terms of organization, variety of disconnected systems where the kids data lives, communication inconsistencies, that would be US public schools. A small army of Claude Sonnets does it well’ish, but it is really expensive, hence “Qwen3.5 397B” could be just a drop in replacement (that’s the hope)
In order to make sense of which local models “do good” I built cupel: https://github.com/tolitius/cupel, and that is the next step: fire it up and test “Qwen3.5 397B” on muti-turn, tool use, etc.. tasks:
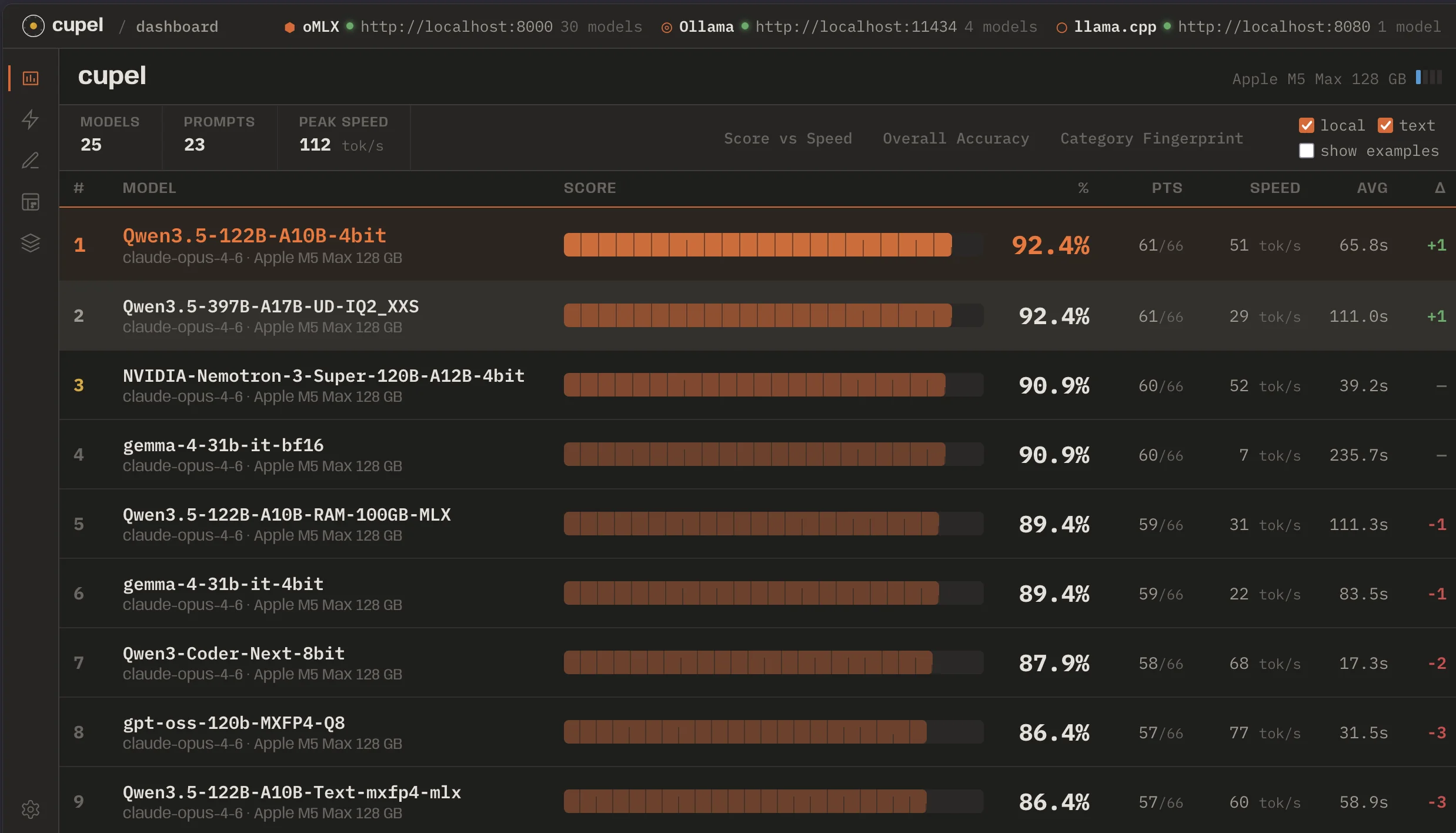
It is on par with “Qwen 3.5 122B 4bit“, but I suspect I need to work on more exquisite prompts to distill the difference.
And, after all the tests I found “Qwen3.5 397B IQ2” to be.. amazing. Even at 2 bits, it is extremely intelligent, and is able to call tools, pass context between turns, organize very messy set of tables into clean aggregates, etc.
What surprised me the most is the 29 tokens per second average generation speed:
prompt eval time = 269.46 ms / 33 tokens ( 8.17 ms per token, 122.46 tokens per second) eval time = 79785.85 ms / 2458 tokens ( 32.46 ms per token, 30.81 tokens per second) total time = 80055.31 ms / 2491 tokens slot release: id 1 | task 7953 | stop processing: n_tokens = 2490, truncated = 0 srv update_slots: all slots are idle |
this is one of the examples from “llama.cpp” logs. the prompt processing depends on batching and ranged from 80 tokens per second to 330 tokens per second
The disadvantages I can see so far:
- can’t really efficiently run it in the assembly, since it is the only model that can be loaded / fits. with 122B (65GB) I can still run more models side by side
- I don’t expect it to handle large context well due to hardware memory limitation
- theoretically it would have a worse time dealing with a very specialized knowledge where a specific expert is needed, but its weights are “too crushed” to give a clean answer. But, just maybe, the “
I” in “IQ2-XXS” makes sure that the important weights stay very close to their original value - under load I saw the speed dropping from 30 to 17 tokens per second. I suspect it is caused by the prompt cache filling up and triggering evictions, but needs more research
But.. 512 experts, 397B of stored knowledge, 17B active parameters per token and all that at 29 tokens per second on a laptop.