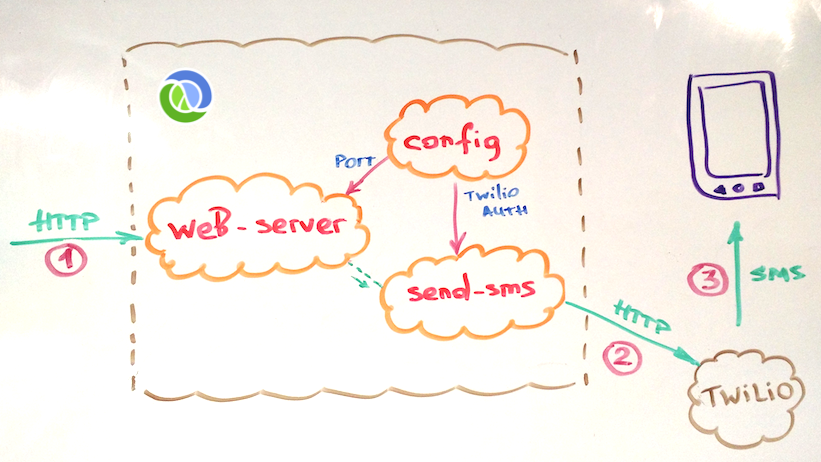
Components or states in mount are kept in Clojure vars, which means that they are accessible from any other namespaces that :require them. They can be made private of course but nothing stops a developer from accessing a private var in Clojure by its full name: i.e. #’any.namespace/any-var.
The flip side is that they “lie near”: they are really easy to use. Can usage of these vars be abused? Of course. Can any “other state management solutions” be abused? Of course. I like my fine balance between “easy” things for development and “simple” things for the architecture.
Several, Local and Simultaneous
In several reddit discussions, people pointed out that since mount keeps components in Clojure vars, those are singletons, hence you can’t have more than one.
While I honestly don’t know how often I would want to have more than one database connection to
* the same database
* with the same host / port / sid
* the same credentials and
* the same schema
(because if any of the above is not the same it would be a different resource / component all together) The example people gave would always come down to this one use case where you want to run a development “system” and a test “system” (potentially more than one) in the same REPL.
The way I do it today is simply running:
boot watch speak test |
in a different REPL.
The need to run multiple systems in the same REPL might have something to do with the limitation of the framework (i.e. component), since you can’t just start and stop parts of a system, which means you can’t iterate quickly with sub systems in the REPL. So instead you end up predefining and running several sub systems simultaneously. But this is just an assumption.
I personally never needed to run multiple “systems” within the same REPL. But I truly believe there are multiple great ways to do things, an I simply can’t just dismiss the fact that people have different development flows.
So I sat down and started to think.
Yurts are Comfy
 Mount relies on the Clojure compiler to tell it what states are defined and what order they should be started / stopped in. So, I thought, I can just use this intel, create a “system” and simply detach it from vars. In other words, using the intel mount has and only using the vars for the bootstrap I can spawn as many local systems as needed.
Mount relies on the Clojure compiler to tell it what states are defined and what order they should be started / stopped in. So, I thought, I can just use this intel, create a “system” and simply detach it from vars. In other words, using the intel mount has and only using the vars for the bootstrap I can spawn as many local systems as needed.
I don’t think this should be mount’s core functionality, plus I really like the way things work with vars and namespaces, but it would be really cool to have these local systems that people can use for testing, whether it is from REPL or for running tests in parallel.
That’s how Yurt was born. The docs go over Yurt’s API (i.e. blueprint, build, destroy) and have a couple of examples of running multiple Yurts simultaneously in the same REPL.
This of course comes down to a choice of either using vars directly or encapsulating components in Yurts, or maybe even both (?) in the same application. But what’s cool about either choice, there is still “nothing to buy”: no full app buy in.